Applications of Machine Learning in Computer Network Security

Machine Learning is one of the booming fields today, but there are some evergreen fields that come up with new challenges constantly, even as our measures against errors, unexpected circumstances, or even deliberate attacks on the system continue to become more formidable.
Networks are one of the evergreen technologies without which most of our real-world activities cannot be completed. Computer networks allow us to efficiently share files and resources amongst the connected systems in a speedy and secure manner. However, the dangers faced by computer networks continues to increase as malicious hackers develop newer methods of using network vulnerabilities to attack the computer systems. There are various algorithms and methodologies to increase network security. Machine Learning algorithms also provide us multiple ways in which we can use the predictive abilities of these algorithms to take faster action based on historical data.
One such example would be to use the K-Means Clustering algorithm to block Denial of Service (DOS) threats. In DOS attacks, a specific IP address is sent more traffic to a network address than the programmers have built the system to handle. In such cases, we can prepare for similar situations in the future by segregating the IP addresses into 2 clusters based on the number of requests sent. The IP addresses sending a relatively larger number of requests can be added to the list of blocked IPs which offers some protection against similar attacks in the future. Once the blocked IPs have been found, we can automate the procedure of blocking the IP by using DevOps tools like Jenkins.
To implement the ideas above, we have some basic pre-requisites:
- Installation of VM with any Linux flavor (I am using RHEL8 VM on Oracle Virtual Box)
- Installation of Jenkins on the VM
Simulating DOS attacks and Collecting data
There are multiple ways and Softwares to simulate different types of security threats to networks. One example is the Hulk DDOS tool. It is actually python script running on Python 2.x. Please look towards reference 3 for more information about how to use the tool.
I have simulated the DOS attack on the RHEL8 HTTPD server using the following command on a Python 2.x environment running on Windows:
python hulk.py http://192.168.1.14:80The IP address is given with the default port number (80) of the HTTPD server.
Once the attacks have been simulated, we can find logs for the HTTPD server in the /etc/log/httpd directory. The logs are stored in the file access_log .We can either work with this data in the RHEL8 VM itself or shift them to the base OS (Windows, Mac, etc).
Applying K-Means Clustering to the Data
Once we have the data on hand, we can start working on building the model. First, we import all the required Python modules and read the data into a Pandas Dataframe
import re
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn import metrics
from scipy.spatial.distance import cdist
import numpy as np
from sklearn.cluster import KMeans
import os
from sklearn.cluster import KMeans#Read the data
d1 = pd.read_csv('/root/mlops_task5/access_log',header=None,names=['C1','C2'])
The data that we just read into the Pandas Dataframe contained multiple components that are not helpful in our analysis, hence we choose only those parts of the data which are actually necessary for us.
d1['IP_Address']=d1.C1.apply( lambda x: pd.Series(str(x).split(" ")))[0]
d1['Time']=d1.C1.apply( lambda x: pd.Series(str(x).split(" ")))[3]
d1['Time']=d1.Time.apply( lambda x: pd.Series(str(x).split("[")))[1]
d1['Method']=d1.C1.apply( lambda x: pd.Series(str(x).split(" ")))[5]
d1['Method']=d1.Method.apply( lambda x: pd.Series(str(x).split('\"')))[1]
d1['Resource']=d1.C1.apply( lambda x: pd.Series(str(x).split(" ")))[6]
d1['Protocol']=d1.C1.apply( lambda x: pd.Series(str(x).split(" ")))[7]
d1['Protocol']=d1.Protocol.apply( lambda x: pd.Series(str(x).split('\"')))[0]
d1['Status']=d1.C1.apply( lambda x: pd.Series(str(x).split(" ")))[8]
dataset=d1.drop(labels=['C1','C2'],axis=1)Once the data has been extracted, the final Dataframe is similar to the image below.
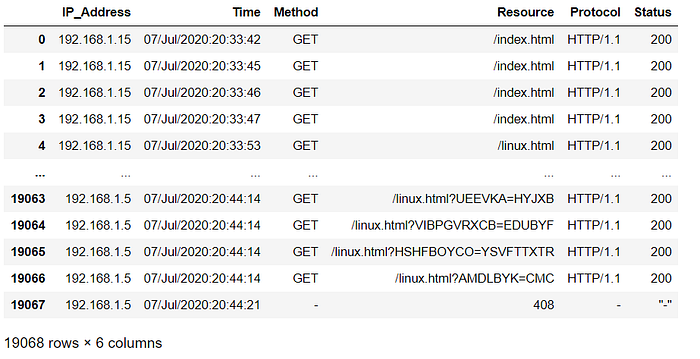
Next, we try to perform data analysis on the data we have.
indexNames = dataset[ dataset['Method'] == '-' ].index
# Delete these row indexes from dataFrame
dataset.drop(indexNames , inplace=True)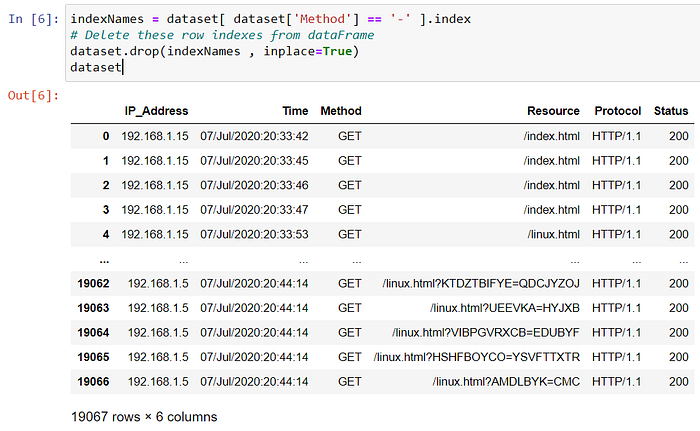
Even in the current data that we have, columns like Resource, Protocol, and Time will not be too helpful in building the model, hence we can drop those columns as well.
dataset=dataset.drop(labels=['Time','Resource','Protocol'],axis=1)Next, we group the data to see the frequency of requests from each IP address and visualize the grouping using a bar plot.
grouped_data=dataset.groupby(['IP_Address','Method','Status']).size().reset_index(name="access_counts")
#From above table, we can identify easily which IP is sending the DDOS attack from.
plt.bar(grouped_data.IP_Address, grouped_data.access_counts, tick_label = grouped_data.IP_Address, width = 0.8)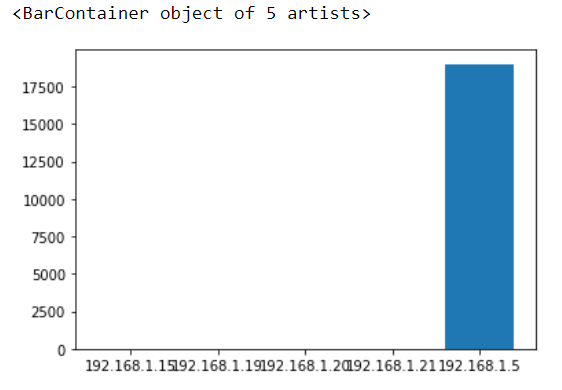
To perform K-Means Clustering, the data that is directly required is the frequency of requests, which is scaled to reduce mathematical bias.
train_data=train_data.drop(labels=['Method','Status'],axis=1)
sc=StandardScaler()
train_data=sc.fit_transform(train_data)#Using Elbow method for optimum K value for K-Means Clustering
distortions = []
K = range(1,5)
for k in K:
kmeanModel = KMeans(n_clusters=k).fit(train_data)
kmeanModel.fit(train_data)
distortions.append(sum(np.min(cdist(train_data, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / train_data.shape[0])plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('The Elbow Method showing the optimal k')
plt.show()#K-Means Clustering model
#Creating Model
seed = 42
model = KMeans(n_clusters=2,random_state=seed)
#Fit and Predict
pred = model.fit_predict(train_data)
#Adding Cluster Labels to dataset
grouped_data['Cluster']=pred
A part of the code above talk about the Elbow method, which is actually used to find the optimum number of clusters which can be used to split the data provided.
However, in our case, we can skip this step since we are clear about how many clusters we want. We need only 2 clusters to separate the IP addresses — one cluster for those IP addresses which may pose security threats and another for the IP addresses which do not pose a threat. In the model training, the random_state parameter is set to definite integer value, so that repeated training on the model will assign the same cluster numbers to each cluster. This consistency in cluster numbers is important in finally filtering out the IP addresses which need to be blocked. Finally, the IP addresses to be blocked are stored in a .txt file.
#Blocking IPs
with open("/root/mlops_task5/blocked_ips.txt","a+") as f:
print(f.read())
for i in grouped_data.index:
if grouped_data['Cluster'][i] == 1:
print("Blocked IP : "+grouped_data['IP_Address'][i])
f.seek(0)
if grouped_data['IP_Address'][i] in f.read():
print("Already present")
else:
print("New IP is added to the list")
f.write(grouped_data['IP_Address'][i]+"\n")
f.close()Automation using Jenkins
To automate our whole idea, we can use GitHub to store both the python script as well the data, and then run the script on the required system (in our case, the VM). The automation can be split into 3 jobs.
Before setting up the jobs, we need to configure some plugins and other system settings on Jenkins:
- Plugins to be installed — GitHub Integration, Email Extension Template, Build Pipeline, SSH, SCP Publisher.
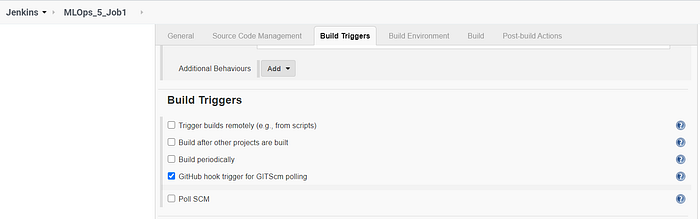
- Set up the Webhook in both Jenkins as well as the GitHub repository.
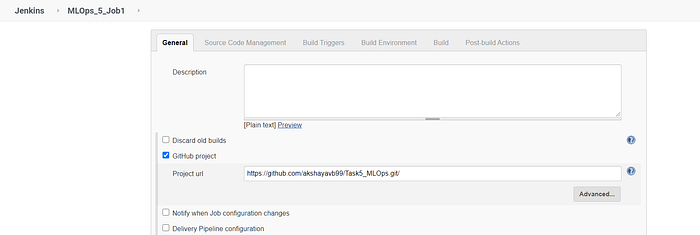
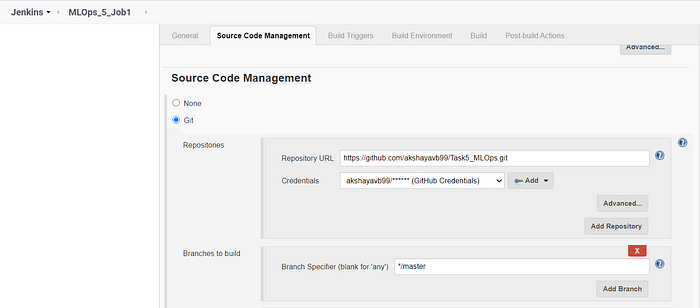
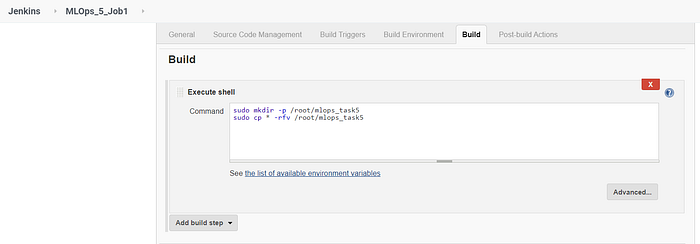
Job 1 is used to transfer the code and the data from GitHub to the local system.
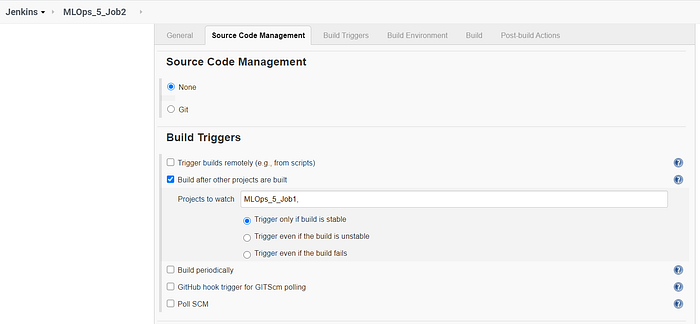
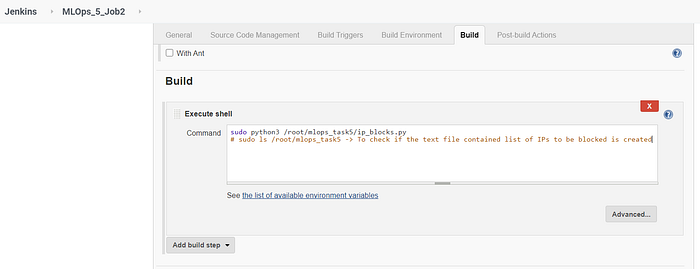
Job 2 runs the python script to find the IP addresses which must be blocked.
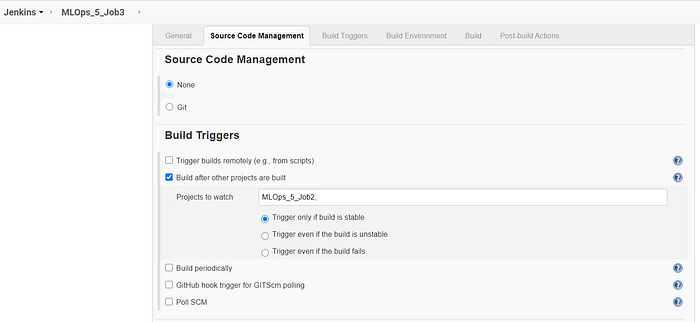
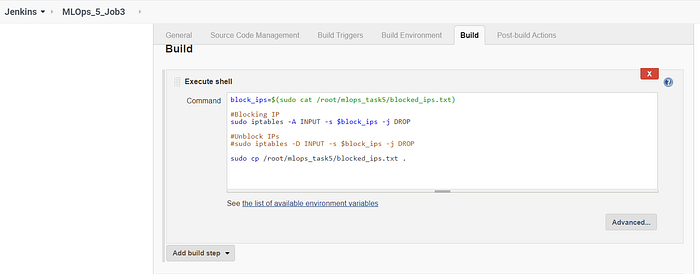
Job 3 performs the actual blocking operation and also copies the text file containing the list of blocked IP addresses into the Jenkins Workspace of Job 3. This is done to make the process of sending custom emails with attachments from Jenkins.
The Email Extension Plugin is used to customize the emails we send based on the status of the Job build. In Figures 14 and 15, the emails are sent based on two triggers — any failure and any success. Each of these triggers has its own customized email content and attachment to be sent to the intended recipients.
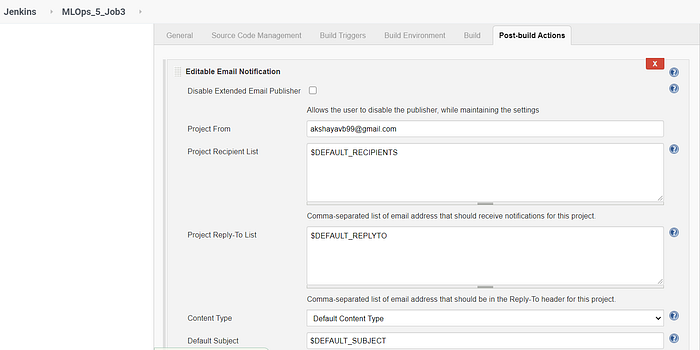
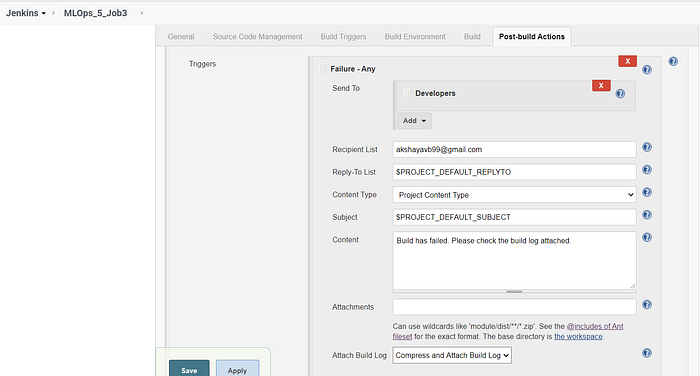
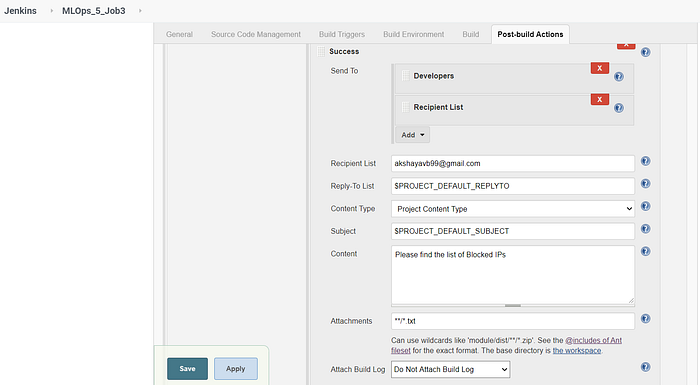
The jobs are chained together so that the successful execution of Job 1 triggers the build of Job 2 and the successful execution of Job 2 triggers the build of Job 3. We can visualize this using the Build Pipeline view provided by the Build Pipeline Plugin.
When the jobs are run successfully, we get the following Build Pipeline view.

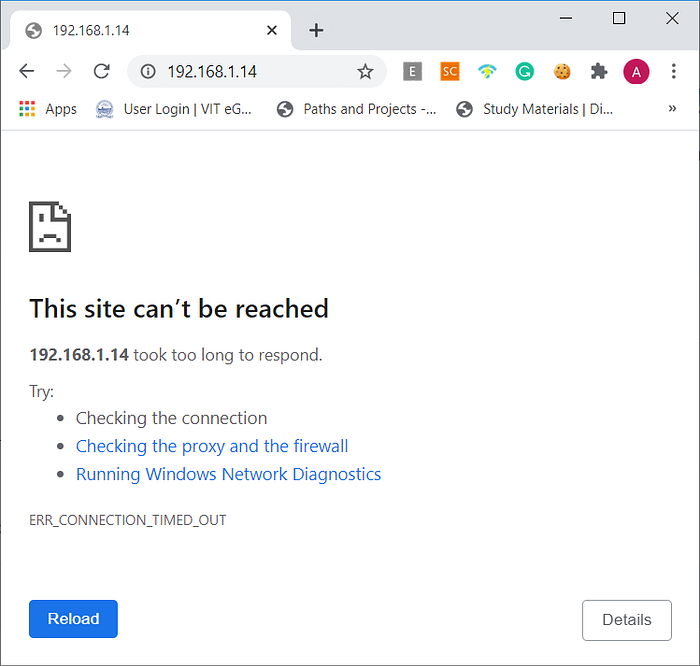
When the IP address 192.168.1.15 is not blocked, we are able to access the webpage index.html on the RHEL8 VM.
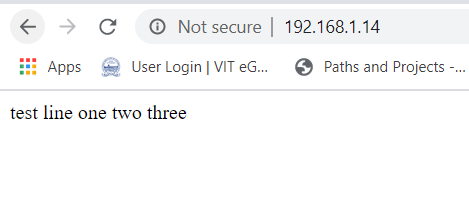
Once the IP is blocked, we are not able to access the same page anymore.
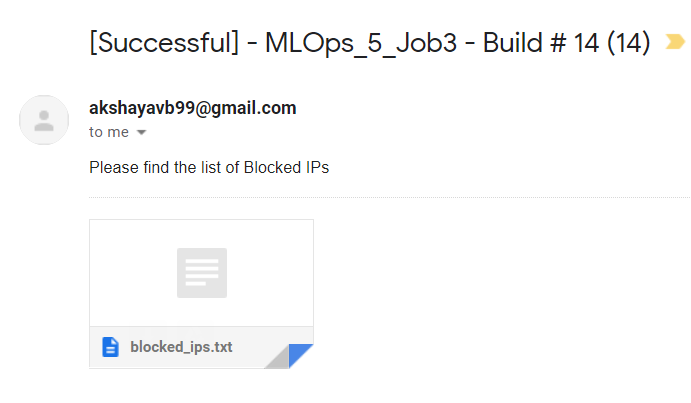
If all the builds are successful, then we also receive a mail, with the text file containing the list of blocked IP addresses as an attachment.
References
- https://www.paloaltonetworks.com/cyberpedia/what-is-a-ddos-attack
- https://www.paloaltonetworks.com/cyberpedia/what-is-a-denial-of-service-attack-dos
- https://allabouttesting.org/hulk-ddos-tool-complete-installation-usage-with-examples/
- https://pythonprogramminglanguage.com/kmeans-elbow-method/#:~:text=The%20technique%20to%20determine%20K%2C%20the%20number%20of,the%20centroids%20are%20closer%20to%20the%20clusters%20centroids.
This work has been done as a part of the MLOps Training program conducted by Mr. Vimal Daga from LinuxWorld Informatics Pvt. Ltd.
Check out more of my work in this program below!
- Working with Jenkins — An Introduction: https://medium.com/@akshayavb99/working-with-jenkins-an-introduction-48ecf3de3c25
- Working with Jenkins, Docker, Git, and GitHub — Part II: https://medium.com/@akshayavb99/working-with-jenkins-docker-git-and-github-part-ii-d74b6e47140c
- An Introduction to Transfer Learning: https://medium.com/@akshayavb99/an-introduction-to-transfer-learning-6b54696fb405
- Integrating ML/DL with DevOps: https://medium.com/@akshayavb99/integrating-ml-dl-with-devops-258dde42e220
- Training Models using Supervisely: https://medium.com/@akshayavb99/training-models-using-supervisely-a57353532abc
